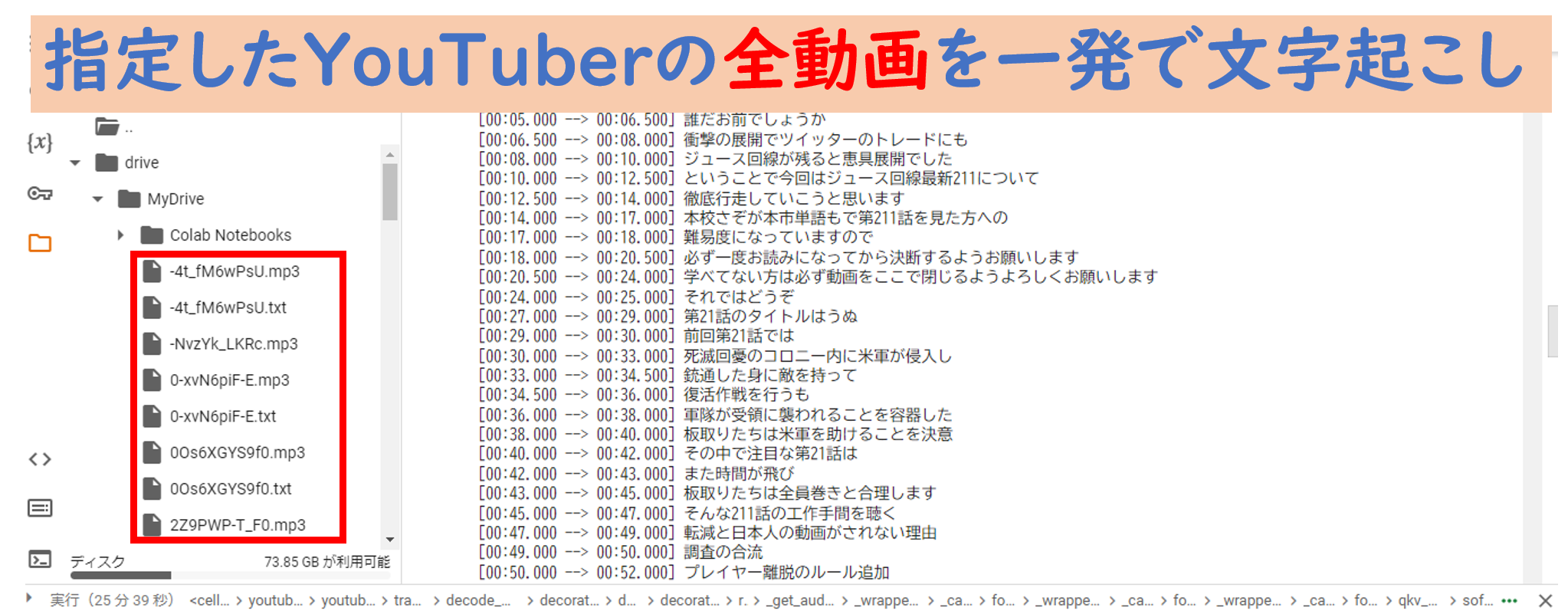
この記事を読むことで以下の方法がわかります。
指定した YouTuber の全ての動画を 連続で文字起こし する方法。
今回はGoogleColab環境(※無料で使用できます。)で動作させます。
※Google Colab は、ブラウザから Python を実行できるGoogleが提供しているサービスです。
GoogleColabにアクセスする
まず初めに以下のURLからGoogleColabにアクセスします。
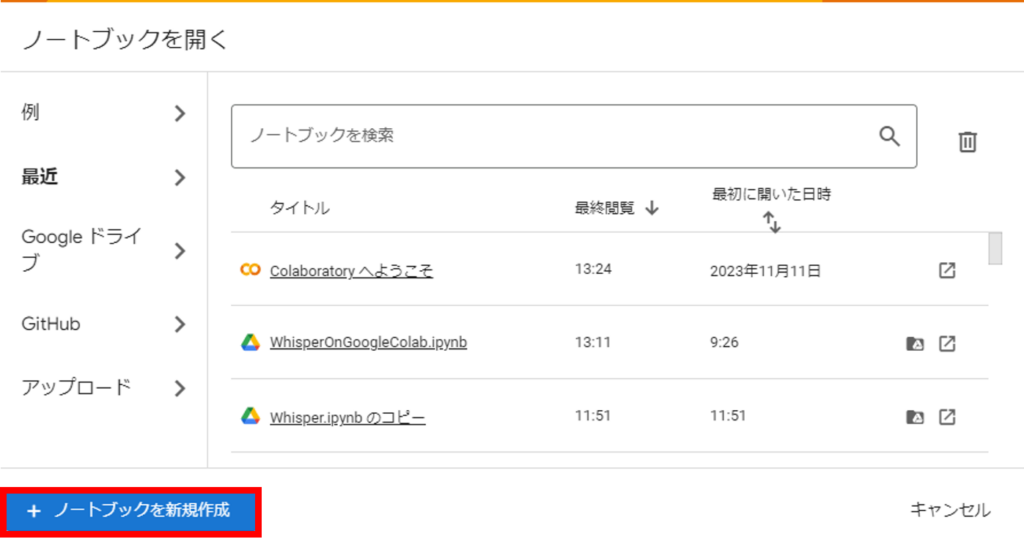
ノートブックの新規作成
以下の画面が表示されますので、ノートブックの新規作成をクリックしましょう。
※詳しくは以下のサイトの「GoogleColabにアクセスする」をご覧ください。
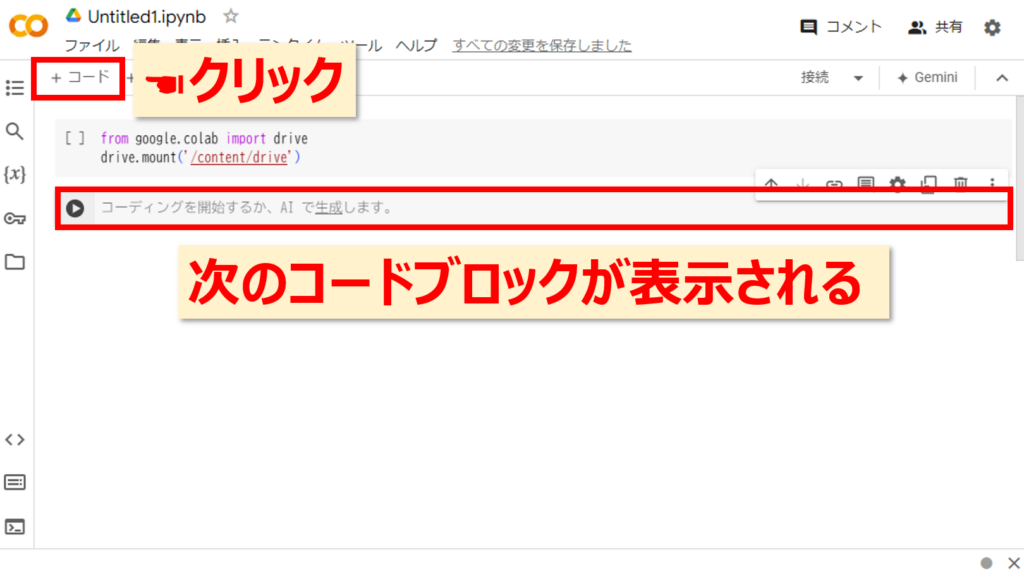
コードの入力
「+コード」をクリックし、コードブロックを表示しましょう。ここにコードを記入します。
GoogleColabのノートブックにプログラムを1つずつ貼り付けましょう。一つ貼り付け終わったらGoogleColab画面の左上にある「+コード」をクリックして枠を増やしてください。
①Googleドライブへアクセスするコード
from google.colab import drive
drive.mount('/content/drive')②文字起こしのパッケージ
pip install -U openai-whisper③YouTube動画のダウンロード
pip install pytubefix④音声ファイルへの変換
pip install moviepy⑤YouTubeAPI
pip install google-api-python-clientメイン実行プログラム
import html
import os
import datetime
import csv
from googleapiclient.discovery import build
from dateutil.relativedelta import relativedelta
from pytubefix import YouTube
from moviepy.editor import *
import whisper
#-------↓パラメータ入力↓-------
developerKey = "ここに自身のAPIキー"
channel_id = "ここにYouTuberのチャンネルID"
#-------↑パラメータ入力↑-------
youtube = build("youtube", "v3", developerKey=developerKey)
videos = [] #videoURLを格納する配列
dt_now = datetime.datetime.now().strftime('%Y%m%d_%H%M%S')
def youtube_search(pagetoken, st, ed):
# APIのビルド
youtube = build("youtube", "v3", developerKey=developerKey)
# APIへリクエスト
search_response = youtube.search().list(
part = "snippet",
channelId = channel_id,
maxResults = 50,
type = "video",
publishedAfter = st, #'2023-01-01T00:00:00Z',
publishedBefore = ed, #'2023-02-01T00:00:00Z',
order = "date",
pageToken = pagetoken
).execute()
# APIからの結果をループ
for search_result in search_response.get("items", []):
if search_result["id"]["kind"] == "youtube#video":
publishedAt = search_result["snippet"]["publishedAt"]
title = html.unescape(search_result["snippet"]["title"])
id = search_result["id"]["videoId"]
url = 'https://www.youtube.com/watch?v=%s' % search_result["id"]["videoId"]
# 文字起こし関数の呼び出し
youtube_to_text(id, url)
try:
nextPagetoken = search_response["nextPageToken"]
youtube_search(nextPagetoken, st, ed)
except:
return
def youtube_to_text(id, url):
# YouTube動画をロード
yt = YouTube(url)
# 最高品質のオーディオストリームを選択
audio_stream = yt.streams.filter(only_audio=True).first()
# オーディオを一時ファイルとしてダウンロード
temp_file = audio_stream.download()
# 出力ファイル名
audiofile = id + ".mp3"
# MoviePyを使用してオーディオをMP3に変換
audio_clip = AudioFileClip(temp_file)
audio_clip.write_audiofile("/content/drive/MyDrive/" + audiofile, codec="libmp3lame")
# 一時ファイルを削除
os.remove(temp_file)
# 出力ファイル名(適宜変更する)
outputfile = id + ".txt"
# 処理
# model = whisper.load_model("small", device="cpu")
model = whisper.load_model("medium", device="cuda")
result = model.transcribe("/content/drive/MyDrive/" + audiofile, language="ja", verbose=True)
# セグメントごとに改行してテキストを取得
segments = result["segments"]
transcript = "\n".join(segment["text"] for segment in segments)
# txtへ書き出し
with open("/content/drive/MyDrive/" + outputfile, "w", encoding='utf-8_sig') as f:
f.write(transcript)
# 2023年1月1日から(ここを適宜変更してください。)
dt = datetime.datetime(2023, 1, 1, 0, 0)
# 20回繰り返し
for i in range(1, 21):
youtube_search('', dt.isoformat()+'Z', (dt + relativedelta(months=1)).isoformat()+'Z')
dt = dt + relativedelta(months=1)使用方法
今回、特定のチャンネルから動画一覧を取得するためにYouTubeAPIを使用しています。YouTubeAPIを使用するにはAPIキーを取得する必要があります。
YoutubeAPIキーの取得
こちらの記事を参考にAPIキーを取得しましょう!

APIキーをプログラムに記載
取得したAPIキーをプログラムの次の部分に記載しましょう。
#——-↓パラメータ入力↓——-
developerKey = “ここに自身のAPIキー“
channel_id = “ここにYouTuberのチャンネルID”
#——-↑パラメータ入力↑——-
YouTuberのチャンネルIDを調べる
こちらのサイトでYouTuberのチャンネルIDを調べましょう。

チャンネルIDをプログラムに記載
調査したチャンネルIDをプログラムの次の部分に記載しましょう。
#——-↓パラメータ入力↓——-
developerKey = “ここに自身のAPIキー”
channel_id = “ここにYouTuberのチャンネルID“
#——-↑パラメータ入力↑——-
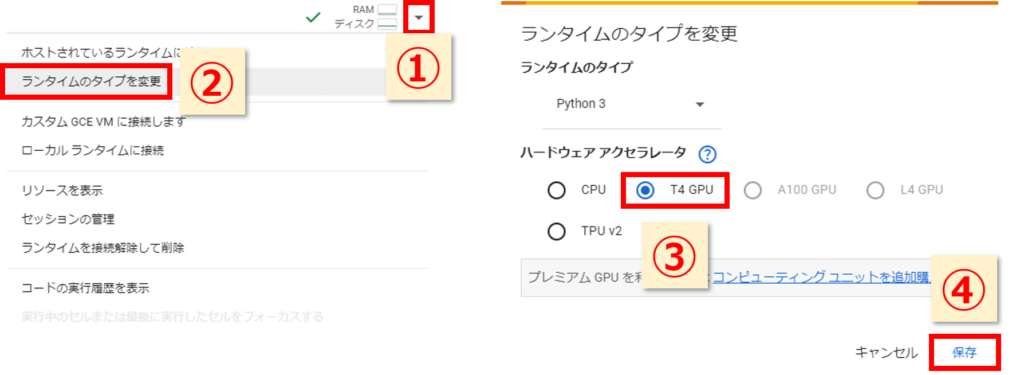
GoogleColabのランタイムのタイプを変更
GoogleColabの画面にあるランタイムのタイプを変更から T4 GPU を選択しましょう。
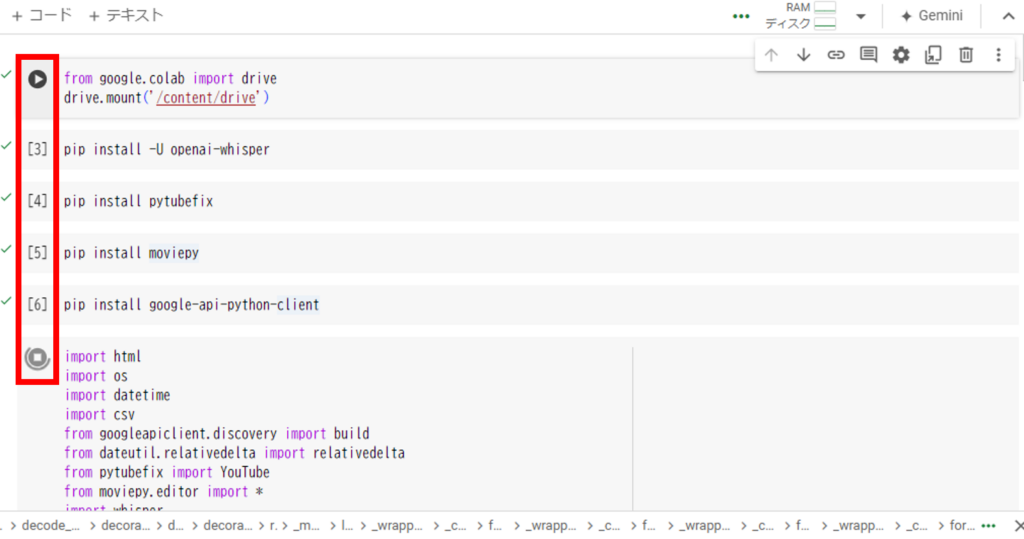
プログラムの実行
上から1つずつ▶を押してプログラム実行しましょう。
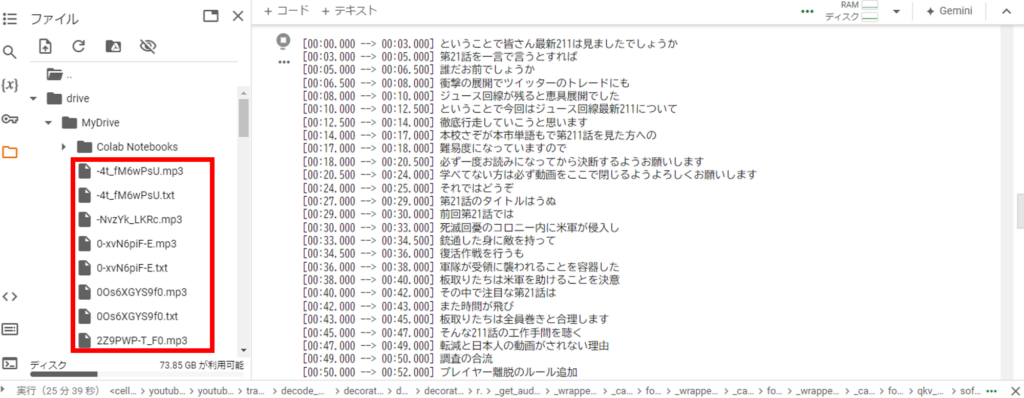
実行結果
実行すると文字起こし結果が「動画ID.txt」として保存されます。
一括ダウンロード
大量の動画を文字起こしした場合、画面上からはひとつづつしかダウンロードできません。その場合は「+コード」で枠を作成し以下のコードを貼り付けて実行してください。
# ダウンロードしたいフォルダを zip 圧縮する
!zip -r /content/drive/MyDrive/download.zip /content/drive/MyDrive
# 圧縮した zip ファイルをダウンロードする
from google.colab import files
files.download("/content/drive/MyDrive/download.zip")さいごに
今回は特定のYouTuberの動画をまとめて文字起こしする方法をご紹介しました。
これにより、動画を見返すことなくどこで何を言っていたかがわかるようになりますね!
ぜひご活用ください!!
※参考にさせていただいたサイトです。
コメント