こんにちはJitanTechです。
今回はYouTubeのURLを指定して文字起こしするPythonプログラムをご紹介します。
では行ってみましょう。
パッケージのインストール
まずは次の3つのパッケージをインストールしましょう。
- pytubefix・・・YouTubeのデータを操作
- moviepy・・・動画編集の自動化モジュール
- openai-whisper・・・文字起こしツール
プログラムコード
from pytubefix import YouTube
from moviepy.editor import *
import whisper
import os
# YouTube動画をロード
yt = YouTube("https://www.youtube.com/watch?v=4O-mCluNTQk")
# 最高品質のオーディオストリームを選択
audio_stream = yt.streams.filter(only_audio=True).first()
# オーディオを一時ファイルとしてダウンロード
temp_file = audio_stream.download()
# 実行ファイルパス
script_path = os.path.abspath(__file__)
script_folder = os.path.dirname(script_path)
# 出力ファイル名
audiofile = "test.mp3"
# MoviePyを使用してオーディオをMP3に変換
audio_clip = AudioFileClip(temp_file)
audio_clip.write_audiofile(script_folder + "/" + audiofile, codec="libmp3lame")
# 一時ファイルを削除
os.remove(temp_file)
# 出力ファイル名(適宜変更する)
outputfile = "output.txt"
# 処理
model = whisper.load_model("small", device="cpu")
result = model.transcribe(script_folder + "/" + audiofile, language="ja", verbose=True)
# セグメントごとに改行してテキストを取得
segments = result["segments"]
transcript = "\n".join(segment["text"] for segment in segments)
# txtへ書き出し
with open(script_folder + "/" + outputfile, "w", encoding='utf-8_sig') as f:
f.write(transcript)使用方法
文字起こしするYouTubeのURLをこの部分に書きましょう!
# YouTube動画をロード
yt = YouTube(“https://www.youtube.com/watch?v=4O-mCluNTQk“)
文字起こしの精度を上げる場合「small」の部分を「medium」または「large」にしましょう。お使いのPCにNVIDIA製のGPUが搭載されている場合は「cpu」の部分を「cuda」にすると高速で処理してくれます。
# 処理
model = whisper.load_model(“small“, device=”cpu“)
実行結果
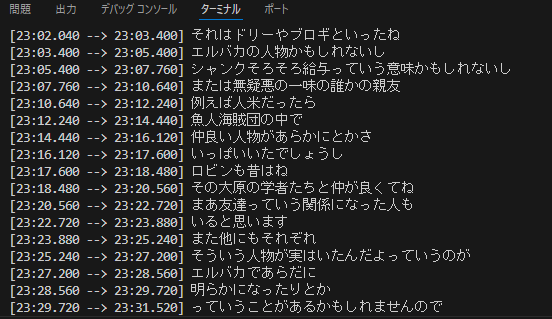
文字起こしされたデータがターミナルに出力されます。
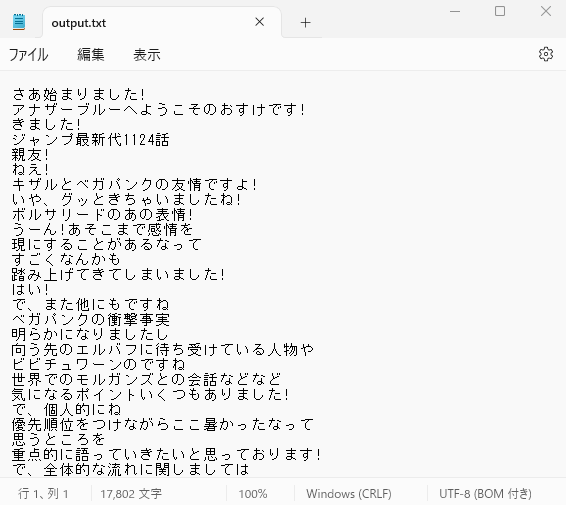
処理が完了すると、文字起こしデータが同じ階層に output.txt が出力されます。
エラーが出る場合
エラーが出る場合は次を確かめてみてください。
Pythonのバージョンは 3.8~3.10 か
これは音声認識ツールWhisperが上記のバージョンしか対応していないためです。
numpyパッケージのバージョンは2より小さいか
Whisperをインストールするとnumpyもインストールされますが、おそらくnumpyのバージョンは2以上jがインストールされます。下の記事ではnumpyをアンインストールしてnumpy1.26.4をインストールする方法をご紹介しています。
さいごに
今回はYouTubeの動画の音声を文字起こしする方法をご紹介しました。
今回ご紹介したWhisperの文字起こし精度はYouTubeの自動字幕よりもはるかにいいですので、需要はあるのではないかと思います。例えば時間がない時に内容を知りたい場合は文字起こしして文章を読むとだいぶ時短できるのではないでしょうか。
便利なものはどんどん活用していきましょう!それではまた。
コメント