OpenAI社が提供している音声認識ツール(Whisper)を用いて音声の文字起こしを実装してみましょう。
私が調べた結果、以下の記事が最もシンプルに文字起こしをすることができました。
しかしその中でもエラーがでることがありました。
エラーが出るとしたら「RuntimeError: Numpy is not available」ではないかと思います。その原因としては2つありました。
- Pythonのバージョンが3.8~3.10でない
- numpyのバージョンが2より小さくない
2024年8月時点ではWhisperを使用できるのはPythonのバージョンが3.8~3.10とありました。本サイトではPython3.9.12を使用しています。
またnumpyのバージョンは2より小さい必要がありそうです。しかしpipでWhisperをインストールしたらnumpy2.0.2が入りました。ですのでこれをアンインストールしてnumpy1.26.4をインストールし直します。
本サイトに記載するプログラムは上記のサイトとほぼ同じとなっていますが、こちらにも記載させていただきます。
ではいってみましょう!
必要パッケージのインストール
以下のコマンドを実行して必要なパッケージをインストールします。
プログラムコード
以下のソースコードをコピーして .py ファイルとして保存します。
import whisper
import os
# 入力ファイル名(適宜変更する)
inputfile = "test.mp3"
# 出力ファイル名(適宜変更する)
outputfile = "output.txt"
script_path = os.path.abspath(__file__)
script_folder = os.path.dirname(script_path)
# 処理
model = whisper.load_model("small", device="cpu")
result = model.transcribe(script_folder + "/" + inputfile, language="ja", verbose=True)
# セグメントごとに改行してテキストを取得
segments = result["segments"]
transcript = "\n".join(segment["text"] for segment in segments)
# txtへ書き出し
with open(script_folder + "/" + outputfile, "w", encoding='utf-8_sig') as f:
f.write(transcript)プログラムの実行
上のプログラムをWhisper1.pyとして保存し、同じフォルダに文字起こしをしたい音声ファイルをtest.mp3として配置します。Whisper1.pyを実行すると、文字起こしされたデータがoutput.txtとして保存されます。
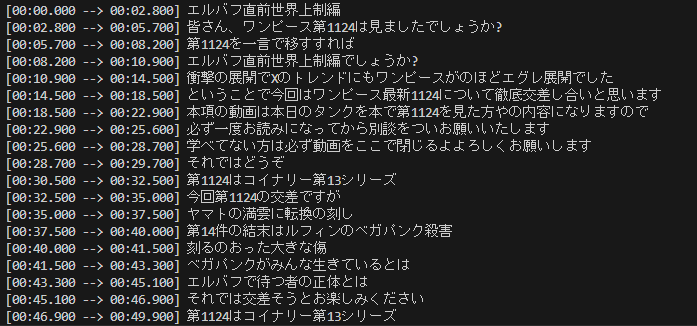
実行すると以下のようにセグメントごとに文字起こしがされます。
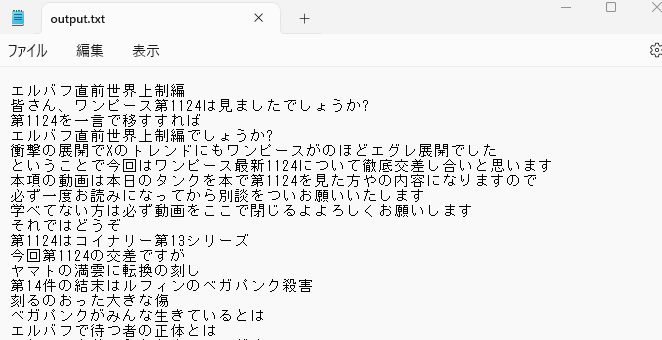
こちらの内容がoutput.txtに出力されます。
精度について
今回プログラムコードでまモデルを「small」にしているため、精度はよくありませんが、以下のようにプログラムを「medium」または「large」に変更して実行してください。驚くほど高精度の文字起こしがされることでしょう。筆者のPCは貧弱すぎてCPU100%となったため、smallで実施しました。
# 処理
model = whisper.load_model(“medium“, device=”cpu”)
GPUの使用について
今回のプログラムではGPUを使用せずCPUのみで実行しています。もしもGPUを使用したい場合は以下のようにプログラムを「cpu」から「cuda」に変更してください。※PCにNVIDIA製のGPUが搭載されている必要があります。また、CUDAのバージョンに応じて、インストールするPytorchパッケージのバージョンが変わるようです。※CUDA(Compute Unified Device Architecture)は、NVIDIA社が開発したGPUプログラム開発環境です。
# 処理
model = whisper.load_model(“medium”, device=”cuda“)
RuntimeError: Numpy is not availableが出る場合
ではここから「RuntimeError: Numpy is not available」が出る原因と対処法を記載します。
原因① Pythonのバージョンが3.8~3.10でない
2024年8月時点では、Whisperを使用するにはPythonのバージョンが3.8~3.10である必要があります。この範囲内のバージョンでないと上記のエラーがでます。対処法としては次の2通りです。
- Pythonをアンインストールして、指定のバージョンのPythonをインストールする
- venvを使用して指定バージョンのPythonを仮想環境に構築する
Pythonをアンインストールして、指定のバージョンのPythonをインストールする
コントロールパネル ⇒ プログラム一覧 ⇒ Python3.〇 ⇒ 右クリック ⇒ アンインストール
つぎにこちらのサイトからhttps://www.python.org/downloads/windows/Python3.9.12のインストーラーをダウンロードしましょう。「Note that Python 3.9.12 cannot be used on Windows 7 or earlier.」の下にあります。
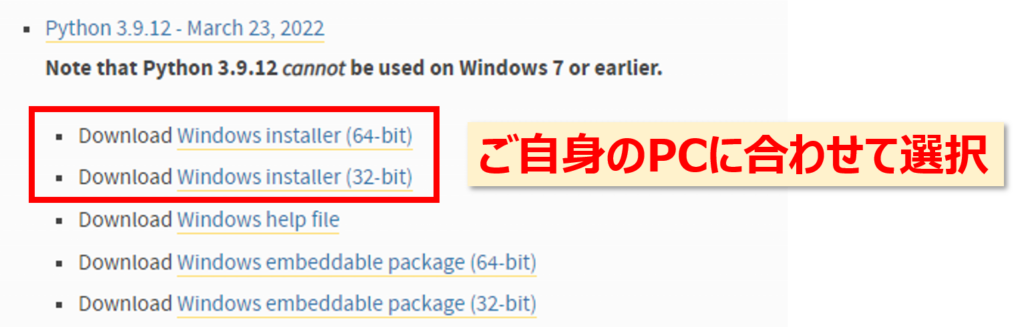
ダウンロードしたインストーラーを実行しましょう、
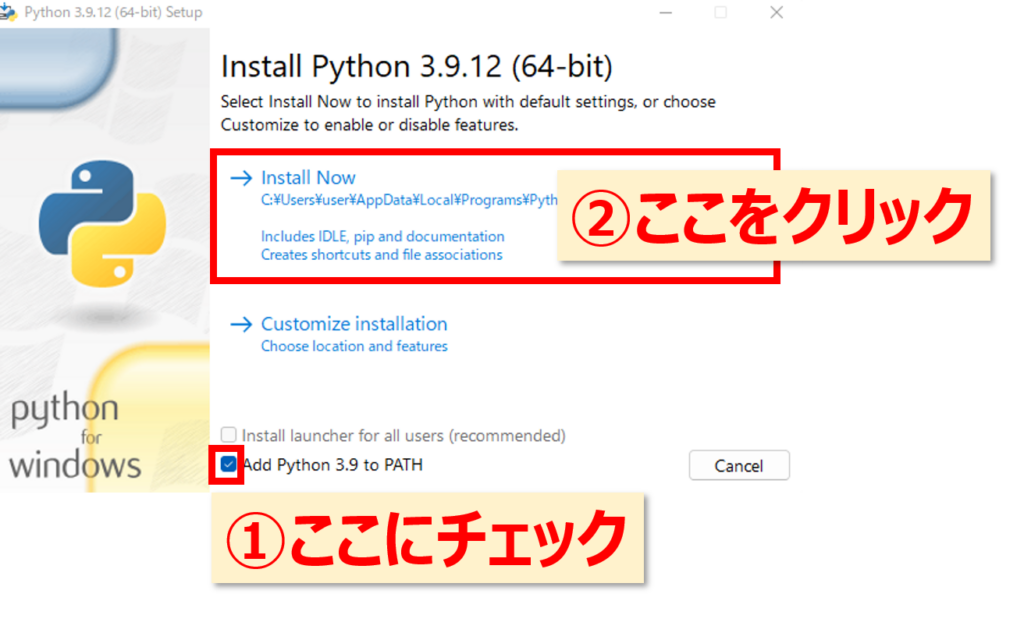
ここまで完了したら、もう一度プログラムを実行してみましょう。それでもエラーが出る場合は原因②にすすみましょう。
venvを使用して指定バージョンのPythonを仮想環境に構築する
venvはPython3.3以上がインストールされている場合、他に何もインストールすることなく使用できます。1台のPCでPythonのバージョンを複数切り替えて使用したい場合はこちらの方法がいいですね。少し手順が長いですので私が参考にしたvenv環境の構築サイトのリンクを貼りますので、そちらを見て構築してPython3.9.12の環境を構築し、プログラムを再度実行してみましょう。

原因② numpyのバージョンが2より小さくない
もう一つの原因としてnumpyパッケージのバージョンが2より小さくないというものです。実は最初の手順であるWhisperをpipでインストールすると、2024年8月現在ではnumpy2.0.2がインストールされてしまいます!ですので、numpyをアンインストールして、numpy1.26.4をインストールしましょう。
numuyのアンインストール
まずはnumpyをアンインストールします、
次にnumpyのバージョンを指定してインストールします。
ここまでできたら、再度プログラムを実行してみましょう!
さいごに
いかがだったでしょうか。
今回はOpenAI社が提供している高精度の音声認識ツールを用いた文字起こしの実装方法をご紹介しました。筆者のPCにNVIDIA製のGPUが搭載されていないため、小さいモデルを使用しての実装となりましたが、みなさんの環境では是非「medium」や「large」を使用してみてください。とても精度が高くて驚かれるかもしれません。
また、今回私が遭遇したエラー以外にもエラーが出て解決できない場合はコメントして頂けましたら調査したいと思いますので、どうぞよろしくお願いいたします。

コメント