以前、ローカル環境で音声の文字起こしをする方法を以下の記事でご紹介しました。
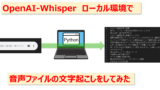
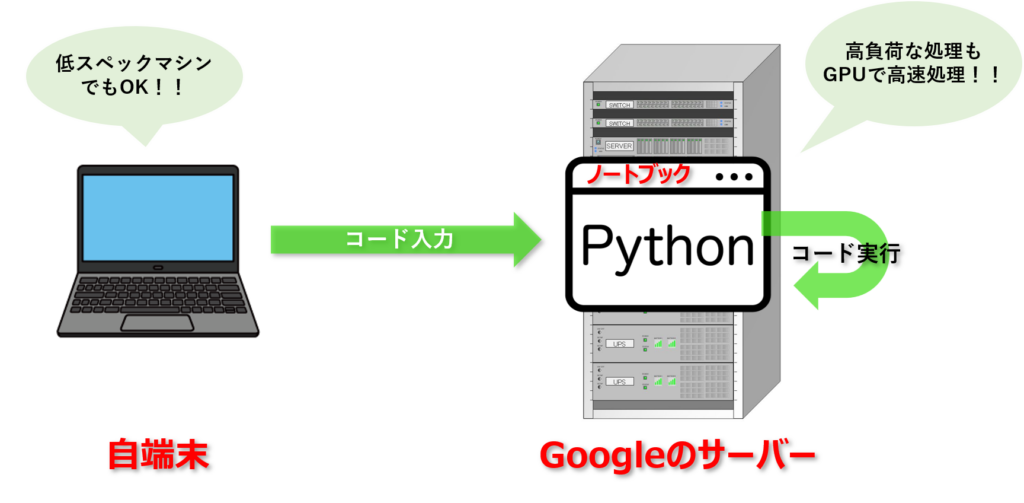
今回は上記の記事とほぼ同じコードをGoogleColab上で動作させて音声の文字起こしをする方法をご紹介します。※GoogleColabは、ブラウザからPythonを実行できる開発環境であり、その実行環境はGoogle社のマシン上で、高性能なGPUを使用することができます。これにより、自端末では時間のかかってしまう処理を高速に完了させることができます。下の画像のようなイメージです。
本記事では、筆者の低スペックマシンでもWhisperのモデル「large」を使用して高速かつ高精度な文字起こしを実現しています。※無料で使用できます。
ではさっそくやってみましょう!
GoogleColabにアクセスする
まずはこちらのGoogleColabにアクセスします。https://colab.research.google.com/?hl=ja
次にノートブックを新規作成します。
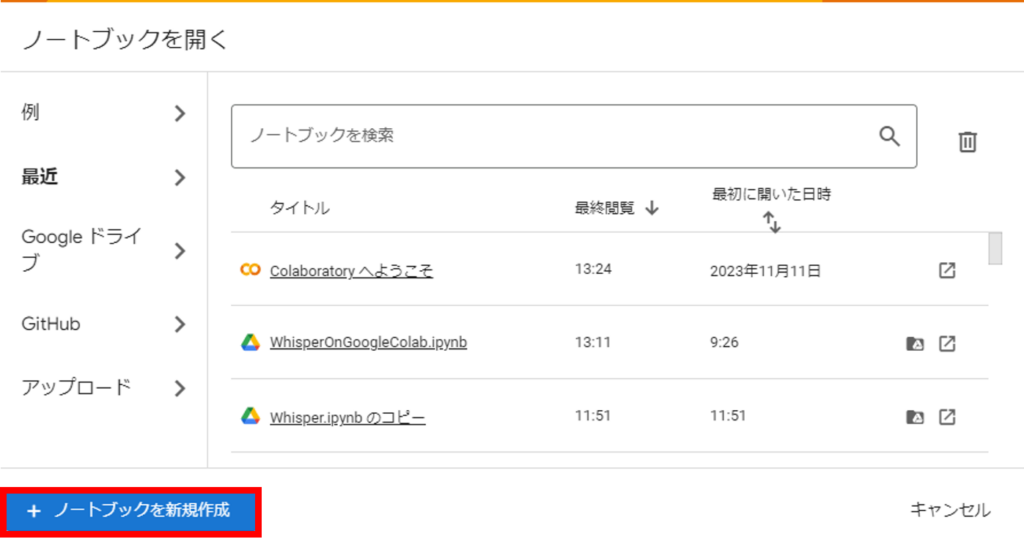
次の画面が表示されます。
プログラムの入力
GoogleColabのノート上に3つのプログラムコードを貼り付けます。
1.GoogleColabにGoogleドライブをマウントするコード
まずは次のコードを一番上のブロックに貼り付けます。
from google.colab import drive
drive.mount('/content/drive')これはGoogleColabでローカルのファイルを選択するために、GoogleドライブをGoogleColabにマウント(使用できる状態)にします。
2.pipで音声認識ツールをインストールするコード
次に、+コード をクリックしてコードの入力欄を増やします。
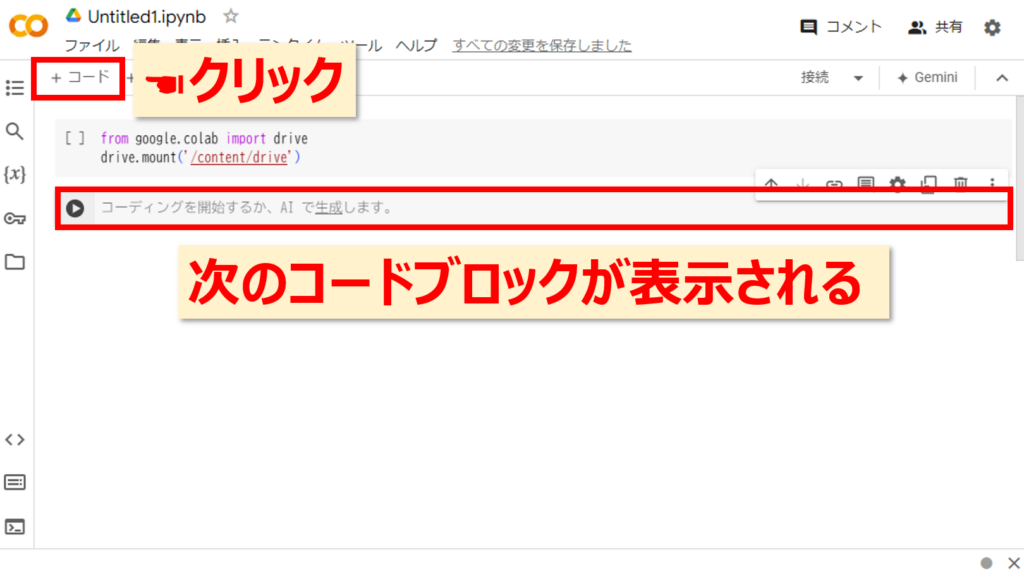
表示されたコードの入力欄に以下のコードを貼り付けます。
pip install -U openai-whisperこれはOpenAI社の音声認識ツールであるWhisperをGoogleColabにインストールします。
3.文字起こしをしてテキストファイルに出力するコード
再度、+コード をクリックしてコードの入力欄を増やします。表示されたコードの入力欄に以下のコードを貼り付けます。
import whisper
import os
# 入力ファイル名(適宜変更する)
inputfile = "test.mp3"
# 出力ファイル名(適宜変更する)
outputfile = "output.txt"
# 処理
model = whisper.load_model("large", device="cuda")
#result = model.transcribe(script_folder + "/" + inputfile, language="ja", verbose=True)
result = model.transcribe("/content/drive/MyDrive/test.mp3", language="ja", verbose=True)
# セグメントごとに改行してテキストを取得
segments = result["segments"]
transcript = "\n".join(segment["text"] for segment in segments)
# txtへ書き出し
with open("/content/drive/MyDrive/output.txt", "w", encoding='utf-8_sig') as f:
f.write(transcript)コードを貼り付け終わった状態
3つのコードを貼り付け終わった状態が以下の画像のようになっているか確認します。
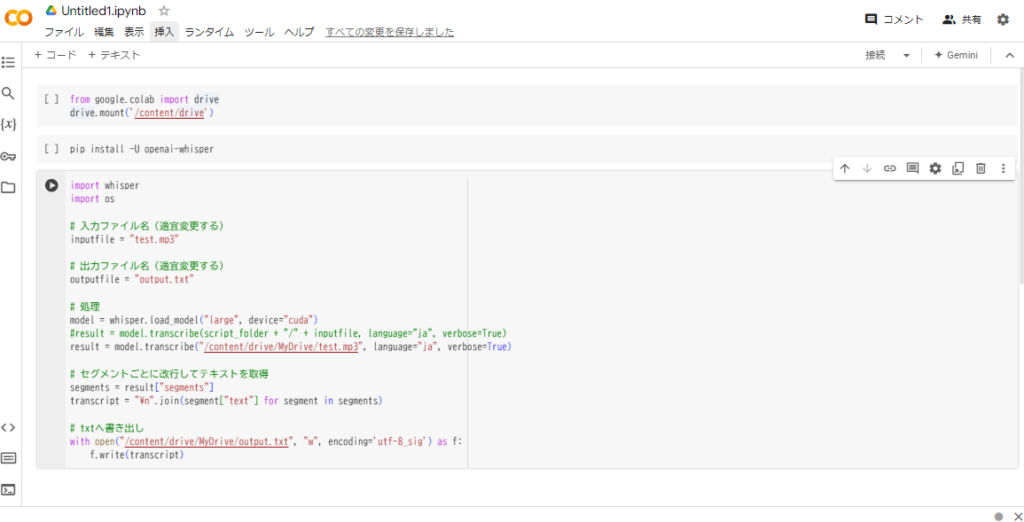
上から1つのブロックずつ実行していきますので、順番は画面の通りになっている必要があります。
ランタイムのタイプを選択
つぎにGoogleのサーバーマシンのスペックを選択しましょう。画面の右上の▼をクリックします。
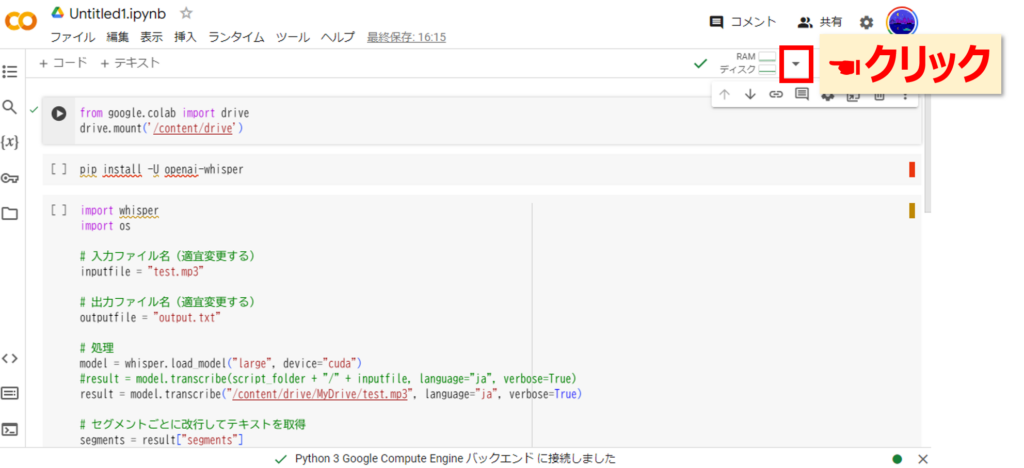
ランタイムのタイプを変更をクリックします。
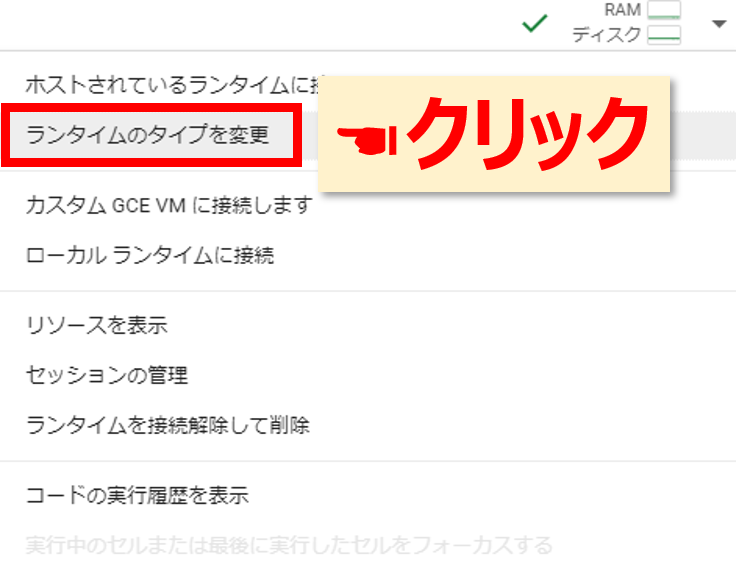
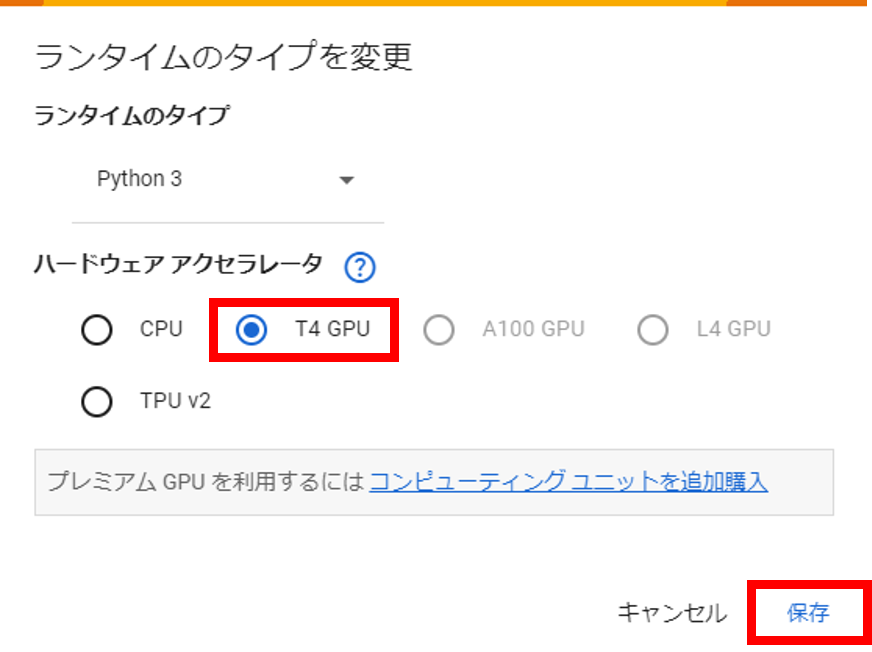
いろいろな種類がありますが、今回はGPUを使用したいので T4 GPU にチェックを入れて保存をクリックします。
プログラムの実行
1つ目のコードを実行
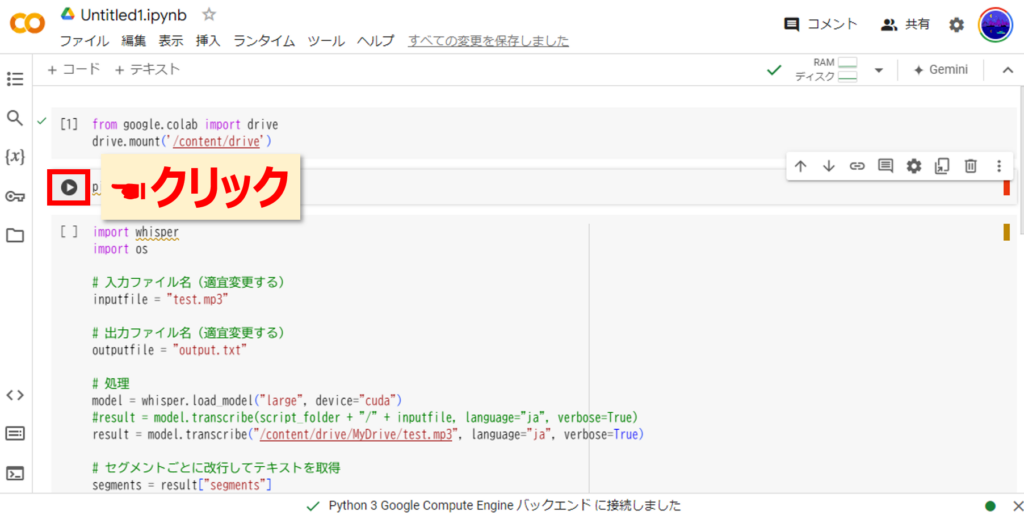
では一番上から実行していきましょう。一番上のブロックの▶をクリックします。
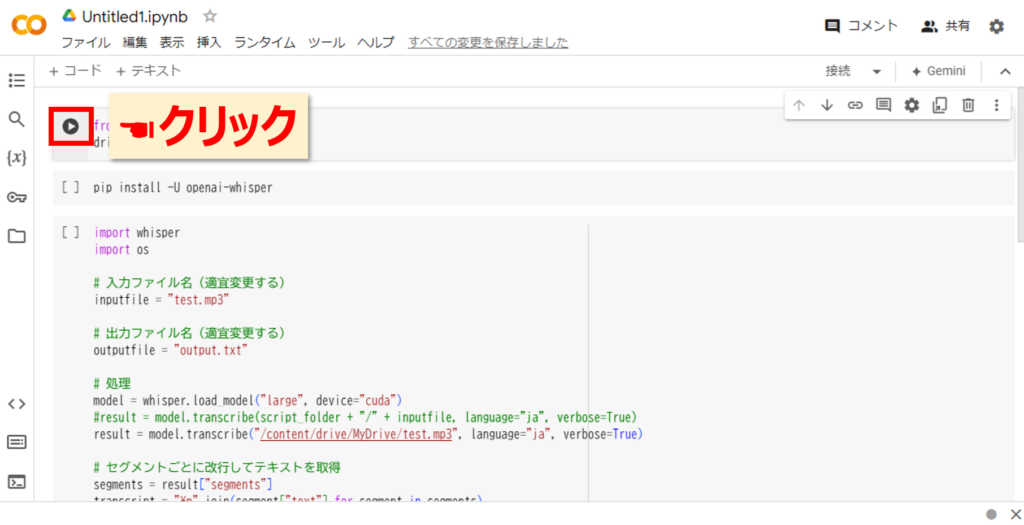
次の画面が表示されますので、Googleドライブに接続をクリックします。※これは自端末のファイルをGoogleColabにアップロードするにはGoogleドライブを仲介する必要があるからです。

Googleドライブのアカウントを選択します。
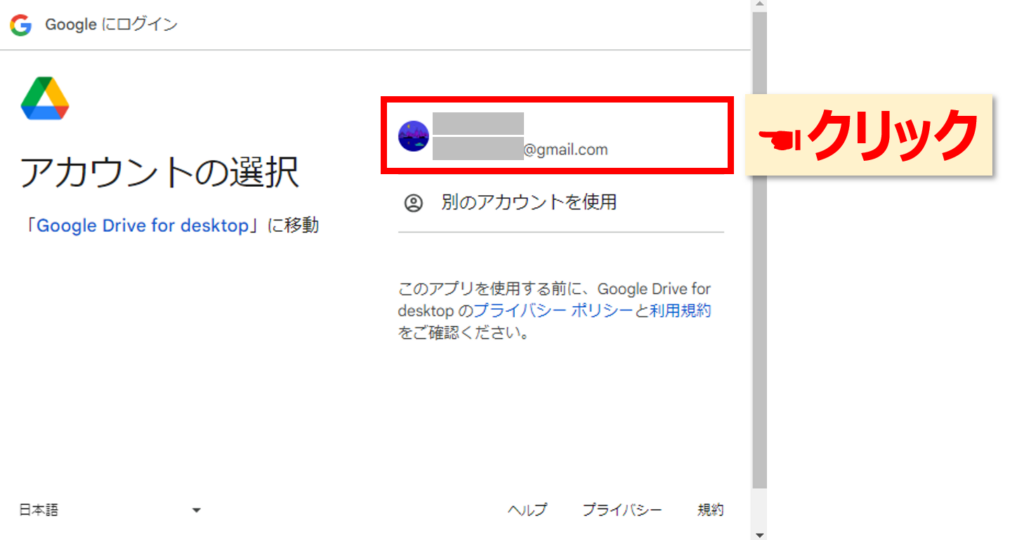
次へをクリックします。
続行をクリックします。
Mounted at /content/drive を表示されればOKです。
文字起こしをしたい音声ファイルをアップロードする
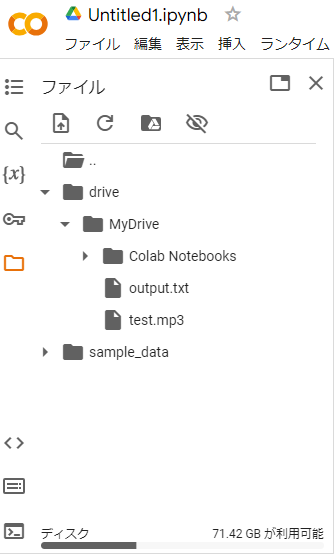
ここで先ほどマウントしたGoogleドライブに、文字起こしをしたい音声ファイルをアップロードしましょう。画面の左側にあるフォルダのマークをクリックします。
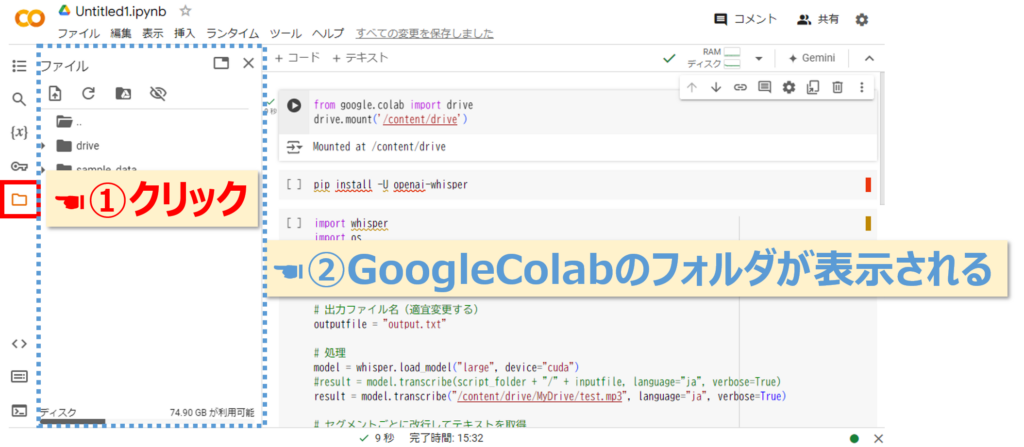
その中で drive > MyDrive フォルダを展開しましょう。すると次の画像のように展開されます。
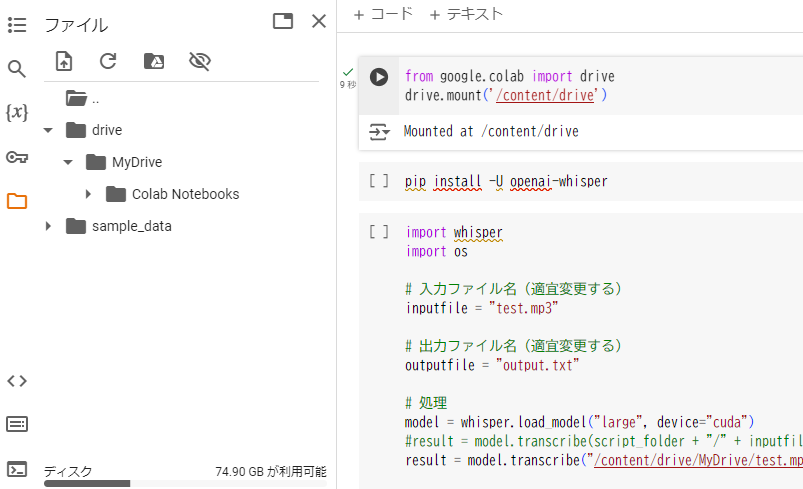
この、MyDriveの中に文字起こしをしたい音声ファイルをアップロードしましょう。やり方はご自身の端末から音声ファイルをドラッグ&ドロップします。
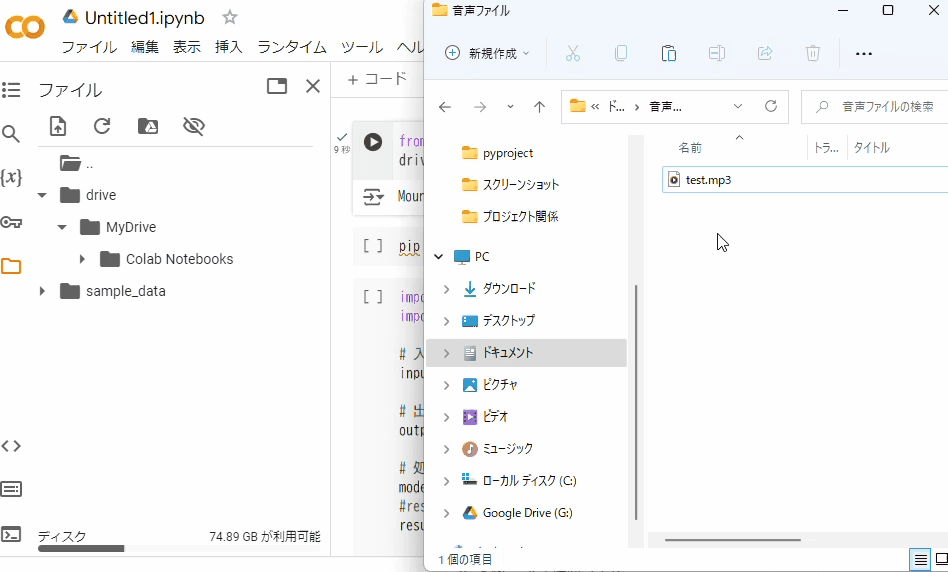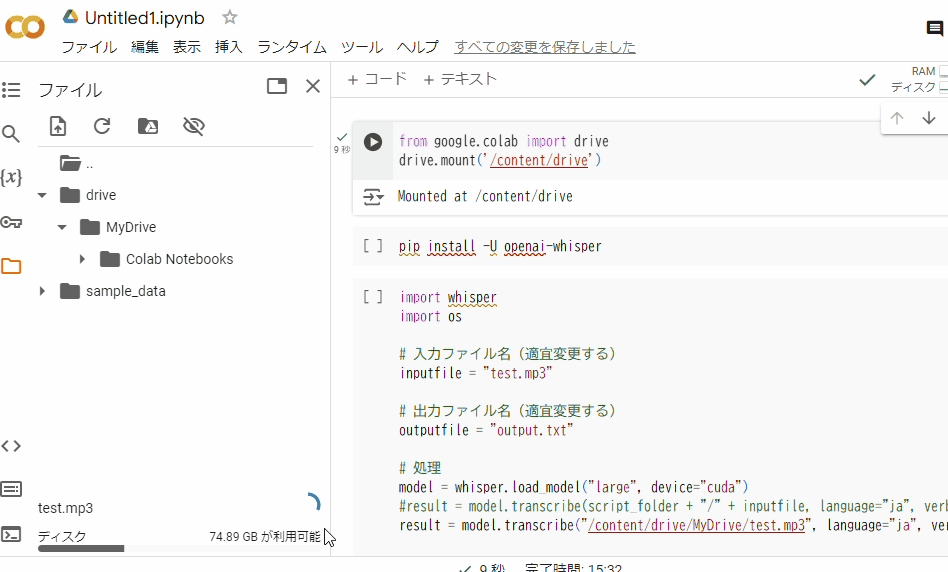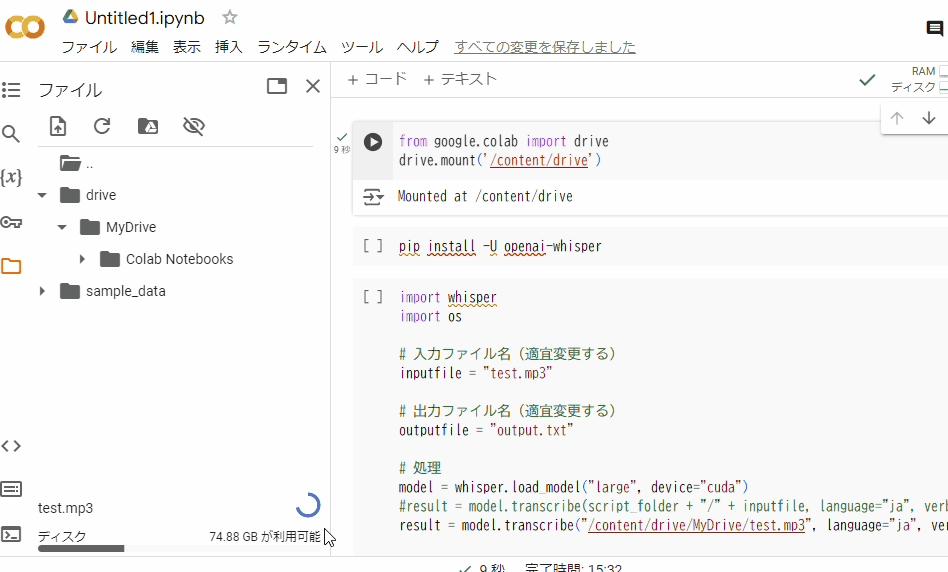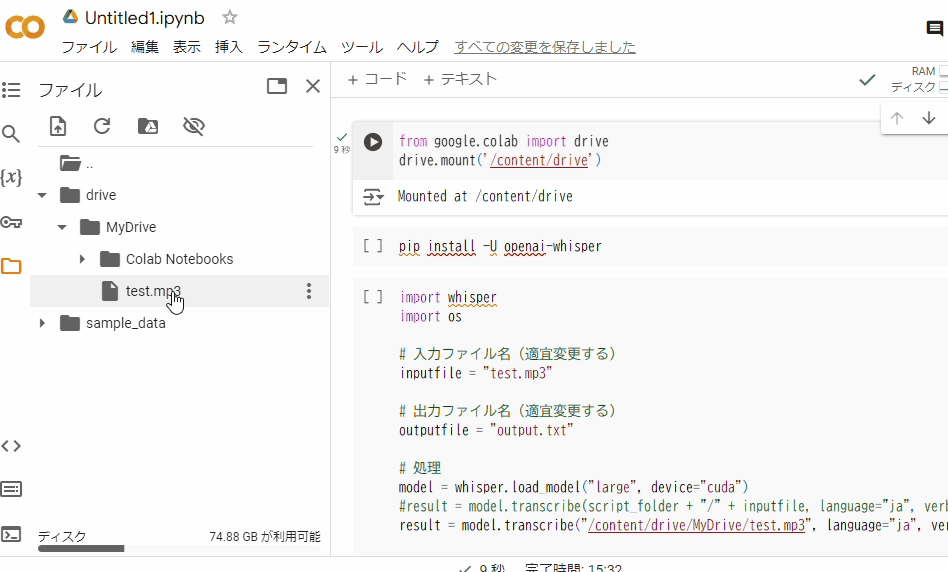
ドロップ先はMyDriveにしてくださいね。またアップロードするファイル名はtest.mp3としています。もしファイル名や拡張子が違う場合はコードのtest.mp3としているところを直接変更してください。
2つ目のコードを実行
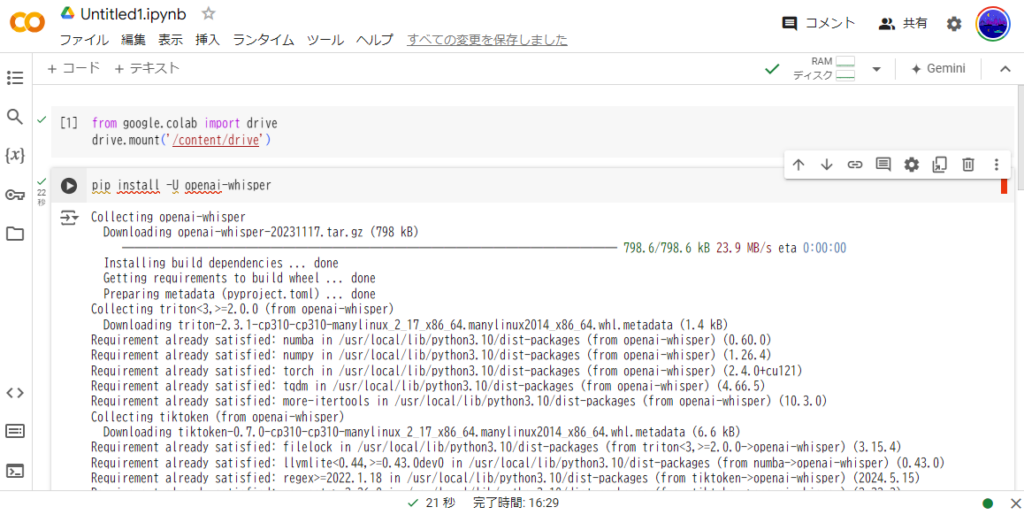
二番目のブロックの▶をクリックします。
音声認識ツールのパッケージがインストールされます。
3つ目のコードを実行
それでは最後に一番下のコードを実行しましょう。
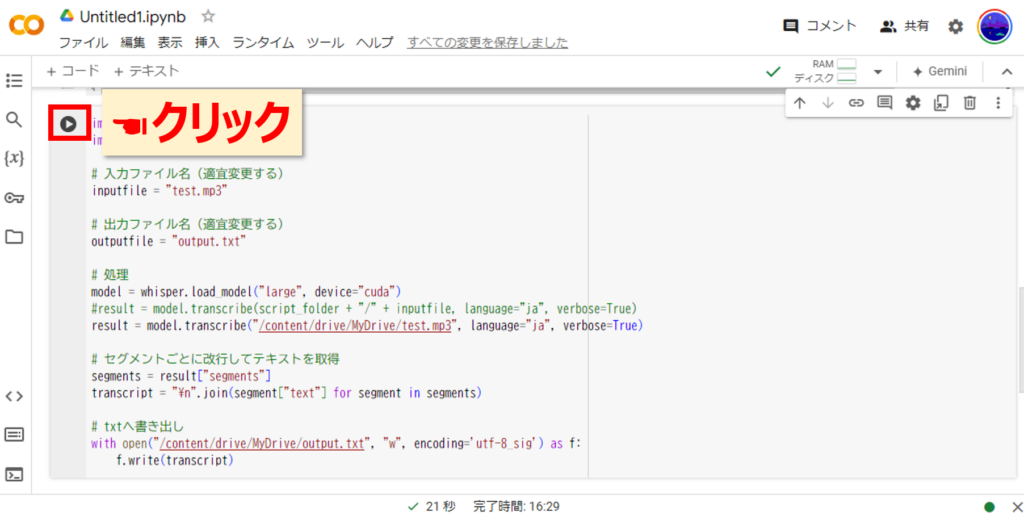
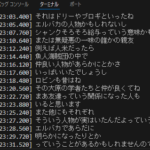
実行するとセグメントごとに文字起こしされた文章が表示されます。
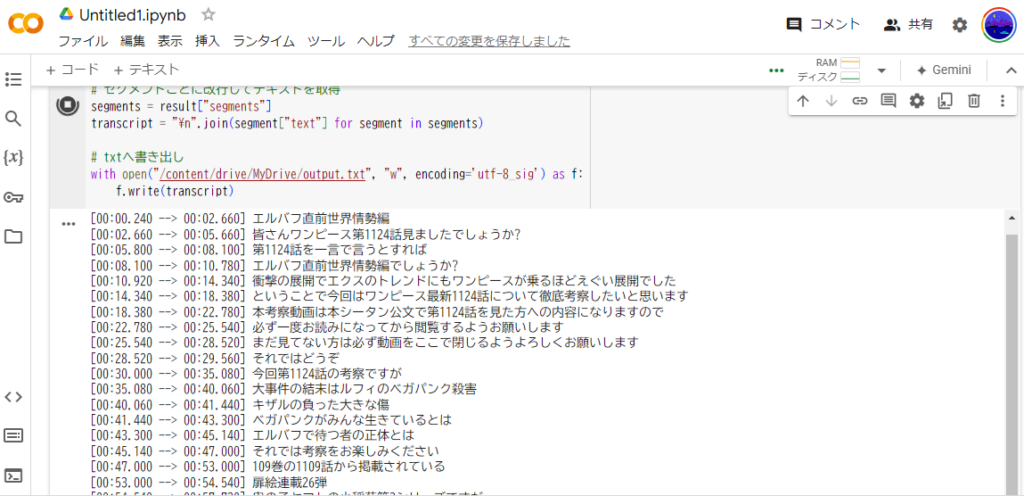
処理が終了したらoutput.txtに文字起こしされています。
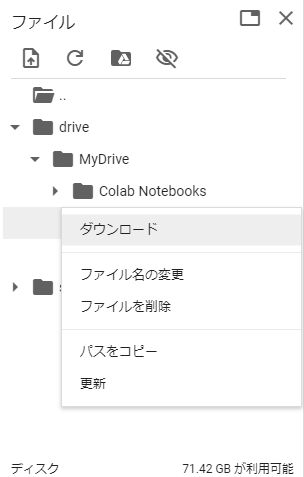
ダウンロードも可能です。
さいごに
いかがだったでしょうか。
今回はGoogleColabを利用して音声ファイルを文字起こしする方法をご紹介しました。
GoogleColabを利用すると高性能なGPUで高速な処理を実現できます。
是非とも今回ご紹介した方法を業務の時短などに生かして頂けましたら幸いです。
コメント